
Benefits of this Mental Model?
Code-Execution is necessary for any cyber attacks. We need to:
- Apply a Divide-&-Conquer approach to understand Code-Execution.
- Learn what really matters to solve it “Upstream” (preventive) instead of “Downstream” (reactive, damage control…).
- Save time to digest “Intel” reports & quickly decide if any further action is necessary.
What background do I need?
For starters, consider reviewing the first two parts of this series:
- Part One covers the fundamental Necessary & Sufficient conditions of any attacks (including physical attacks), & that “Threat Accessibility” to vulnerable assets is like “oxygen” for cyber attacks.
- Part Two explains a reusable Mental Model (Attack Life Cycle model) to think like an attacker in terms of their tactical objectives.
Attacks that intercept users’ IDs & passwords don’t need Code-Execution on victims’ devices (aka Adversaries-in-the-Middle in general). Cheap deception tricks users with fake interfaces, capturing secrets (including One-Time-Pins) for attackers’ to abuse. The following case is legit messages mixed with a scam. Some malicious URL links even contain brand names like bank or telco names.

Code-Execution may involve some forms of deception (e.g. looks like PDF icon but actually an executable file), like a message to convince you that you have some delivery invoice, a resume for HR personnel to review… but it can also be carried out WITHOUT any form of users’ interactions as shown in the next diagram.
How do “Bad” Codes get in?
An attacker send payloads either:
- directly to network ports or electrical interfacing (e.g. Bluetooth, USB ports…); or
- to human receivers without requiring so call “exploits”.
For the first case, attackers simply scan networks (Info Gathering phase) to find a vulnerable point to exploit.
Just to shed a bit more details on how reusable exploits are, it is as brainless as scanning tool automatically figuring out which exploit to use for specific version of vulnerable software, then deliver it to vulnerable port or service…& Boom (like the poop-hit-the-fan below)! Remote attackers get a foot-hold into your networks just like a recent MS Exchange vulnerability & some smarty pants “researcher” released a free POC that works!
For the infiltrating client zones without exploiting directly exposed vulnerabilities, it usually requires some deception to get victims to interact with some “bad stuff”. Either way, remote attackers will need some form of signal that malicious Code-Execution was successful. Internet provides both the payload-delivery & signaling channel.
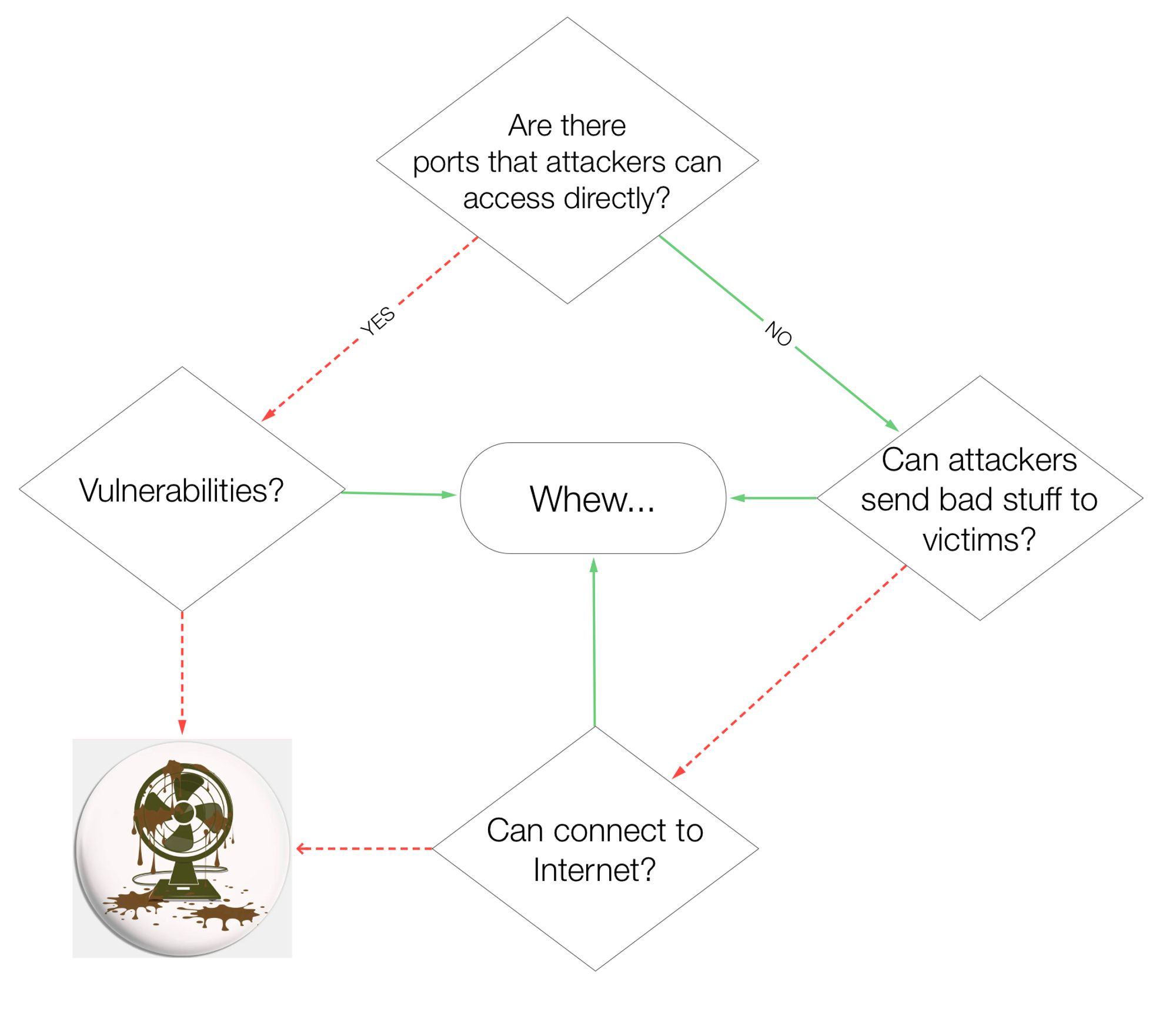
Code-Execution aka Arbitrary Code-Execution, means running any instructions (aka codes) on the target. Publicly exposed networks ports are the so call “Low Hanging Fruits” mentioned in my Part 2 of this series. More exposures ⇒ more “oxygen” (accessible) for “fires” (attacks) to burn. To reduce risks (probability):
- keep such services’ ports OUT OF THE Internet & within a private network accessible only by valid users AND devices
- patch vulnerable software regularly
- DO BOTH to starve “oxygen” for attacks.
How about assets without exposed ports or services? Using a TV remote analogy. A successful Code-Execution is like attackers stealing remote-controls of your TVs. It happens so quickly that in a few eye-blinks, backdoor installed & remote C2 session is started. With remote control, attackers assert Command & Control (C2) over compromised assets that are usually not reachable directly. Attackers can issue commands & codes to move on to other sub-objectives (boxes below) once C2 sessions are acquired.
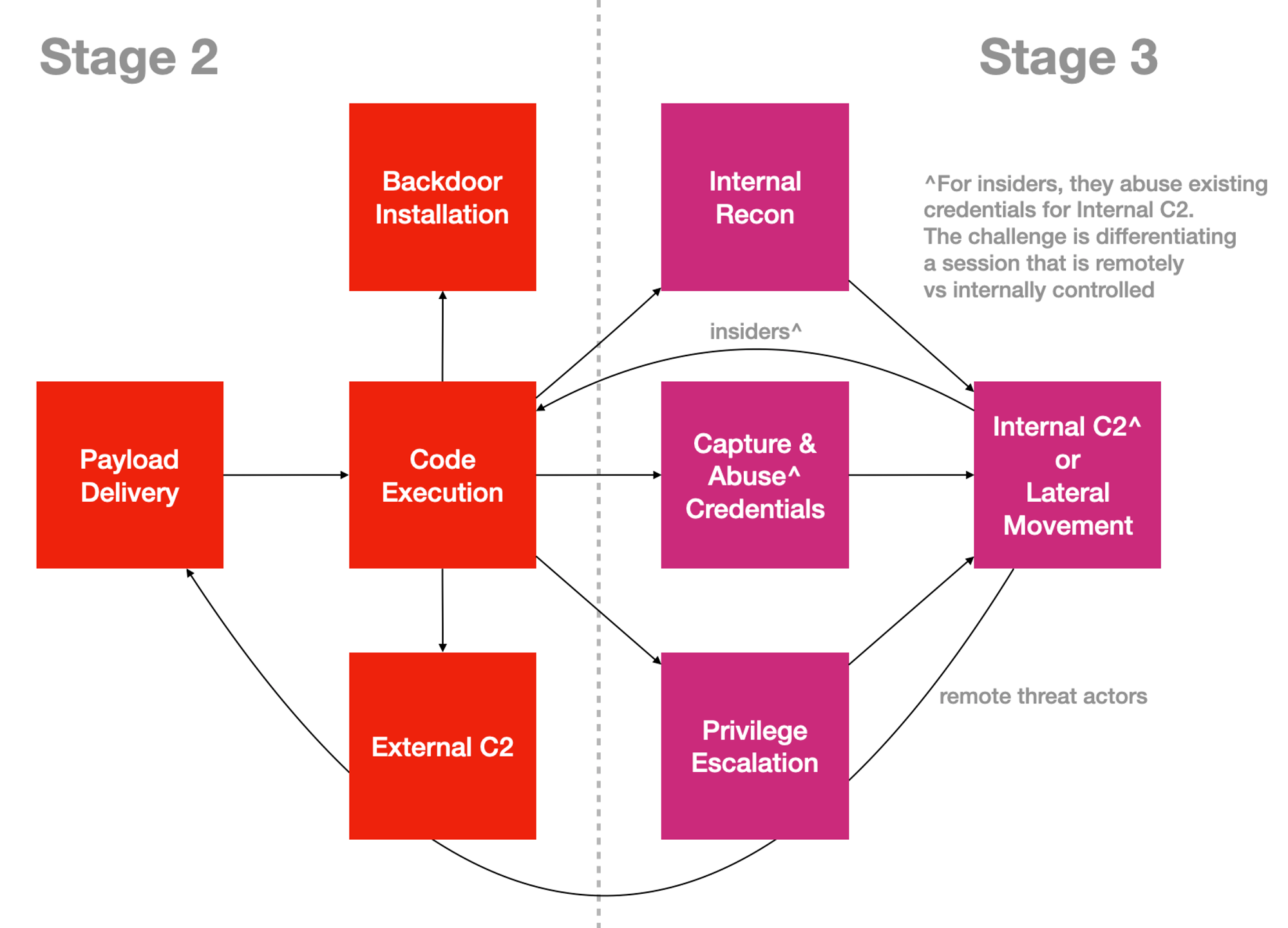
Every attack sub-objective requires some form of Code-Execution. Part 1 covers strategy, Part 2 explains how attackers RINSE & repeat their offensive TTP? And here, Part 3 focuses on the key to most offensive campaigns: Code-Execution, the enabler for most offensive tactical outcomes. First thing first…
How do users run codes?
- Programs are stored “codes”, stored in file system of most devices’ disks.
- A user interacts within a device or host session, triggers program executions with input actions (e.g. mouse clicks, screen-taps… but OS will start some automatically too).
- Operating Systems read program files, loads codes as instructions into memory & executes within CPU(s).
- A Program can have multiple running instances known as Processes.
- Processes perform various activities accessing storage, network & any other resources.
Three Types of Code Execution
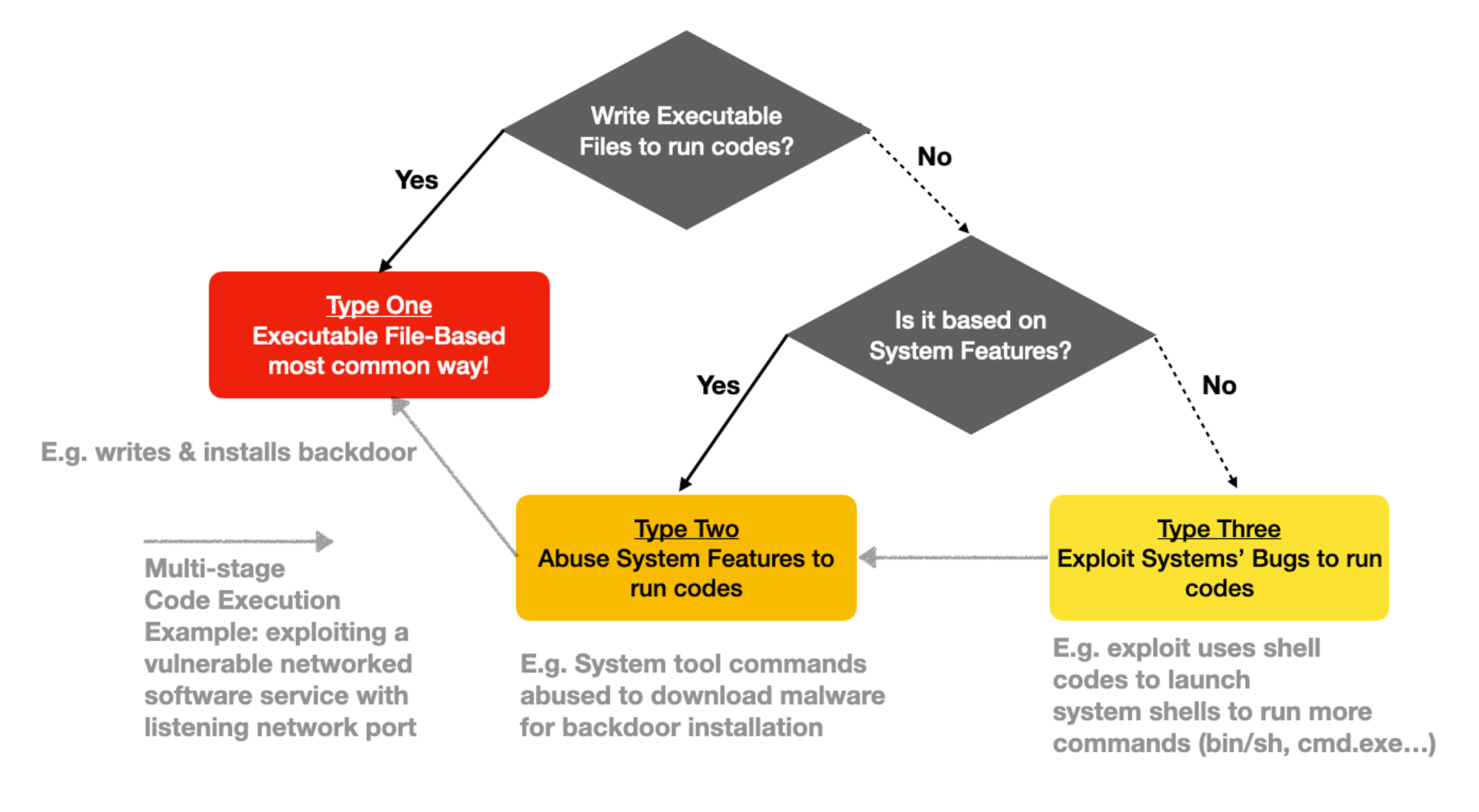
There are essentially only THREE types of Code-Execution:
Types | Characteristics | Examples |
1. Executable File Based | Executable files need to be written to disk & loaded directly by OS. This forms the majority of Code-Execution regardless malicious or not. This is a system feature, applicable to all modern OSes.
Someone (e.g. download shadow IT apps) or something needs to write & then execute such payloads. Which leads us to the next 2 types. | 95% (of millions) of Ransomware samples analysed over the years by VirusTotal are executable files: Portable Executable (aka EXE) & Dynamic Link Libraries (aka DLL)… but why executables?
They are usually faster. Encrypting large disks full of files will need that performance. It’s also harder to reverse-engineer than let’s say a ransomware-script! |
2. Abuse System Features | Any System Tools or Mechanisms that load codes that may be textual or binary, but not an executable format. Very reliable & evasive since host controls tend not to block system tools to avoid support issues.
Again, system features. | Microsoft Office macros (Windows), Python scripts (Linux, Windows, MacOS…)
Command line tools within various OSes. |
3. Exploit System Bugs
| NOT features but bugs. Exceptional ways that perform unintended actions. Can be triggered remotely (aka Remote Code Execution) & run purely in memory without writing to disks.
When it comes to exploiting bugs, attackers NEED TO KNOW the version & make of the software (or even hardware) vulnerabilities. They do so by scanning for these vulnerabilities that are exposed on the Internet. Which makes exploits a big deal for exposed assets! | Exploits typically load shell-codes. Recall from the 1st flow-chart, a exposed network port is an example of entry point to exploit.
|
It’s either abuse system features or exploit bugs. Code-Executions tend to be chained together (aka Multi-Stage), e.g: Exploit (Type 3) → Shell scripting (Type 2) → download & install a Ransomware Executable (Type 1). So is this model applicable to NON-Windows platforms?
Applicable to Internet-of-Things?
Someone said (I can’t remember who): Linux is the new firmware! Majority of IoTs are powered by Linux. Whatever codes compile for Intel chips, can be re-compiled to port to let’s say ARM processors. The output files of such code compilation → Type 1 - Malicious Executable!
But why bother to go through the trouble of compiling again & again for different hardware when Python is widely installed by on Linux: Type 2 → Abuse a System Tools that is commonly present!
Oh how about Log4J vulnerability that was raging recently? When it comes to bad stuff, Java is close to Write Once, Exploit Anywhere: Type 3 → Exploit & Profit!
Applicable to Web & Mobile Apps?
Don’t feel like paying for that cool Android or iOS app? Let’s “Root” (escalate privilege within) the smart-phones to install apps NOT from official app stores. Some “savvy” users like “free” Android APKs, which are binary executable files: Type 1 problem.
A poorly implemented Web application that uses the infamous Eval() function (offered by scripting languages such as Python, Javascript, PHP…): Type 2.
A common used Bluetooth stack with flaws that can be exploited remotely to trigger Remote Code Execution at privileged level without any user intervention or notice: Type 3.
Chasing After “BAD” is ENDLESS
Look! A SOC engineer in his natural habitat, running in a Threat-Mill… (as narrated by Sir David… neh just kidding, but the burn-out is for real!)

Now let’s us use your newly acquired Mental Model & review prevailing industry practices w.r.t each type of Code-Execution.

Dan Heath’s book “Upstream” challenges readers to look “Upstream” to be more preventive, instead of solving “Downstream”. In this case chasing after artefacts generated after problems occurred (e.g. malware sample files, hashes, C2 server addresses…) is a “Downstream” Sisyphus’s curse.
Code-Execution Types | Current “Solution” | Issues |
1. Executable File Based | Signature based Anti-virus that scan files that are written. Even so call “Next-Generation” with AI or Machine Learning is nothing more than tracking “bad” at larger scale with algorithms.
Conventional App-Control is pain-in-the-arse to manage. | Mutating programs infinitely is free and rapid.
Evasion is essentially free with so much public knowledge online.
When attackers get denied with this method? Simply move on to NO-written-executable techniques or abuse system features. |
2. Abuse System Features | Subscribe-to, DIY or mix of both “Detection Engineering” that attempts to develop & maintain detection methods to spot offensive techniques. Some may be rule-based, some with so call AI or Machine Learning. | Very expensive in terms of OpEx & CapEx.
Even if you manage to keep talented (but expensive) staff, there’s only so much “Threat Hunting” to do; you don’t know what you don’t know.
Many host sensors are susceptible to evasion that DOES NOT require privileged (aka Userland) Code-Execution.
|
3. Exploit Bugs | Network Intrustion Prevention Systems which started as signature-based to stop known payloads from being delivered to targets. Nowadays, start-ups will slap AI or Machine-Learning tagline to turn such NIPS to yet another “Next-Gen” product. | There are NO signatures for Zero-Day (unpublicised) exploits.
Alert fatigue & challenge to link to host activities. Brute-force linking of every network activity to host activity is usually untenable as it incurs performance penalities & huge resources to analyze the linkages. |
We are paying “Downstream” subscriptions (some party to maintain DenyLists, chasing after “bad”) for signatures of transient artefacts, while attackers are evading sensors for FREE rapidly. There will always be significant lag & blind-spots with DenyList approach (aka Blacklist, apologise if anyone gets offended with color).
Solving it “Upstream” Requires a Shift of Focus
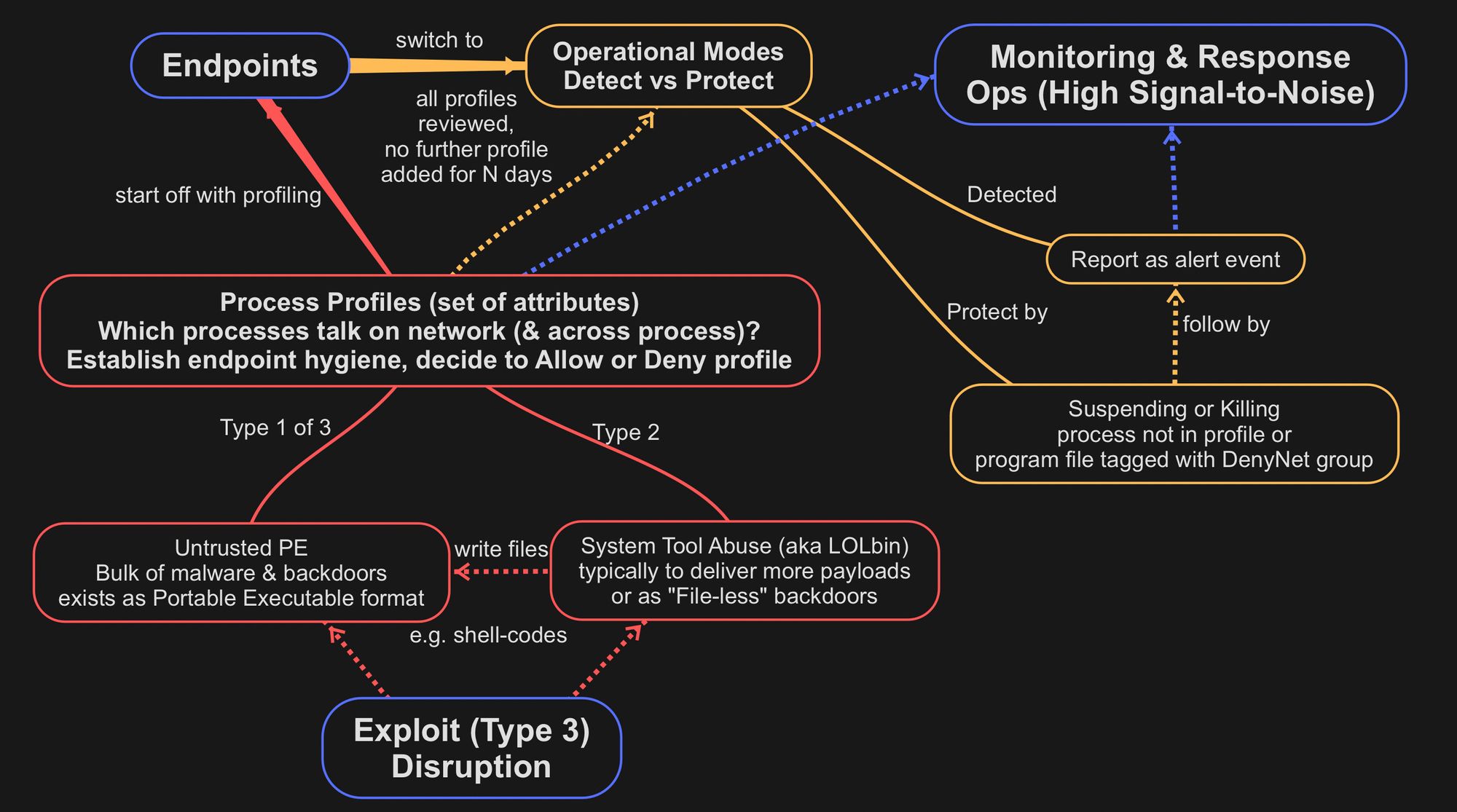
Away from an infinite set of “bad” transient artefacts, but to focus on identifying a finite set of legitimate processes that requires network & cross-process communications within your networks & use-cases.
But why just these two activities!? Remember the TV remote control analogy? A majority of bad processes (e.g. Trojan, RAT…) need to “call” back to a C2 server the Internet. But even before a C2 session can start, ALL Multi-Stage Code-Execution will eventually egress for more payloads. Reusing a diagram I shared in my Part 2 of this series:
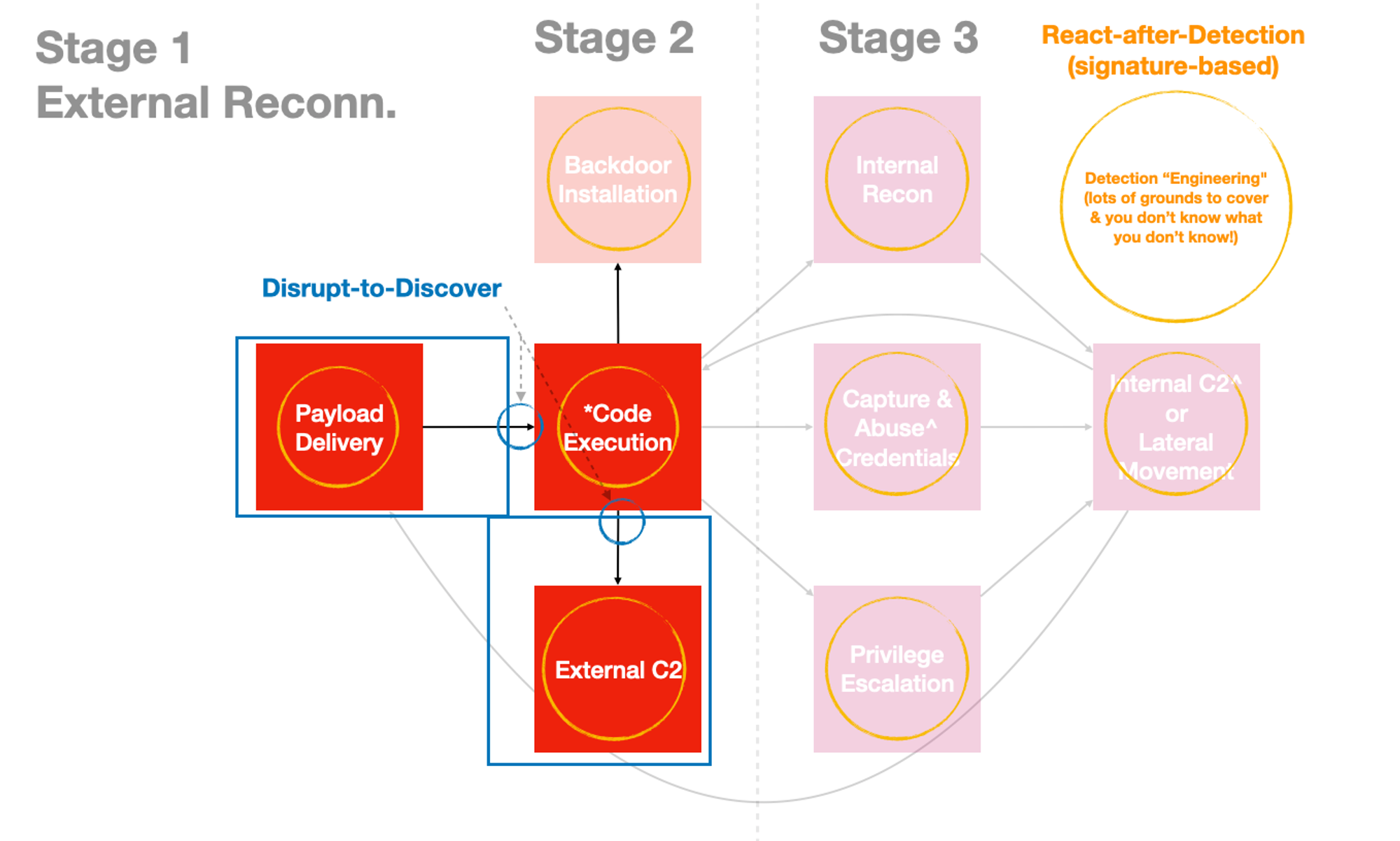
But Jym… there’s removable storage, file-shares & other NON-network channels to deliver malware. Which is why disrupting Type 1 Code-Execution without the administrative pain & cost matters!
“Detection Engineering” for those faded-out boxes is essentially “Downstream” seeking.

Focus on the 2 blue circles in the earlier diagram to disrupt attacks “Upstream” (early) to lower probability of “Downstream” problems!
Disrupt Code-Execution without a DenyList?
The “Downstream” ways focus mainly on DenyList. The “Upstream” approach inverts it by building painlessly (aka process-profiling) an “AllowList” that is relevant to your networks.
By ensuring legitimate processes that regularly communicate on networks & across-processes function properly, we effectively deny other processes NOT in this list.
As a result, much higher Signal-to-Noise ratio without the alert fatigue. Even if there were infrequent legit system processes that may end up being suspended for reaching out to the Internet, backend monitoring operations have that benefit of time to investigate.
Suppose it were an attack C2 session, attackers would have advanced within networks quite quickly even before defenders can react & contain manually. Infrequent (because the frequent network-bound processes would have already been profiled, reviewed & either allowed or denied) disruptions lead to discovery (solves we don’t know what we don’t know) of something to learn & decide. So how are we going to disrupt each type of Code-Execution?
Code-Execution Types | Evasions | “Upstream” Counter-measures |
1. Executable File Based | Mutating programs is free and rapid.
Evasion is also cheap or free to hide executables within allowed file formats.
Attackers likely to shift to NO-written-executable techniques, abuse system features or exploits | Use Application Control that is based on File Ownership. The main idea is whenever users can change executable program files, so can attackers. All Type 1 Malware files written by processes running with user’s privilege are owned by the affected user. Most people just won’t Run-As-Admin to read their Office Word documents.
Conventional app-control based on paths, signing or signed files & allow-list databases are costly to maintain & have plenty of loop-holes. File Ownership approach denies any written executable not owned by trusted system-user or groups.
There are scenarios (e.g. developers’ zone) where running or testing programs owned by users is somewhat a norm, these will need special treatments.
But beyond that, many apps have gone “cloud” as SaaS (Software as a Service), such apps are essentially dedicate browsers (e.g. Electron apps). Only a few native common apps like Video Conference cum chat, Browsers & Email clients are usual stuff that need to talk online.
For enterprises & even Critical Sectors with centralized software deployment. Programs should be deployed with ownership that DENY standard users from overwriting.
There’s really no good justification to NOT have app control. File Ownership based allow-listing effectively disrupt a majority of malware without the high cost & complexity of updates. |
2. Abuse System Features | There’s a dedicated open-source project tracking Living-off-the Land techniques: https://lolbas-project.github.io
Also no shortages of public knowledge-based of evasions that abuse system features. | The whole point of initial access of infiltration is to establish C2 sessions. Of course, before a C2 session for attackers, payloads need to be delivered to targets without being blocked.
So instead of trying to track “bad”, we track legit processes that are suppose to talk on network & across processes. Regardless of system processes or user-programs, those that often communicating on the network & across-process can be profiled & remembered for a given (specific to) host.
During profiling, we also take the opportunity to check for any prior infections. There are systematic ways to do this instead of just depending on highly experience talents.
We effectively reduce the problem scope from infinite Type 1 & 3, to a much smaller set of Type 2. |
3. Exploit Bugs | Network transmissions are encrypted, exploit payloads simply fly under the radar & directly to the vulnerable targets.
It defeats the whole purpose of transport confidentiality when we introduce network decryptors just to scan for “bad” packets!
When attackers know of the 1st two disruptions approach, then s/he would need to come up with exploit that can either write malware in a way that has allowed ownership &/or inject into legitimate process to communicate outbound… | We are not trying to stop exploits from being delivered to the target, but disrupting multi-staged executions. The Code Execution kill-chain is broken when Type 1 & 2 cannot further continue after being disrupted. |
Talk is cheap! Let’s see it in action!
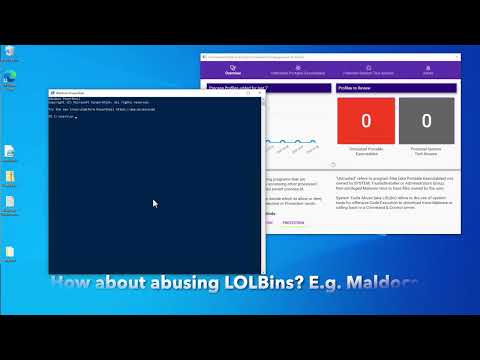
As shown in the video, once we switched endpoint to Protect mode, well… it’s protected! By learning this Mental Model, it helps the analysts to decide DURING THE PROFILING PROCESS.
Upcoming revision will be posted on https://free.edr.sg & links to hands on tutorial for Windows Event monitoring will be updated @ https://jym.sg/cyber-security-in-7-weeks! Now that you have a better idea of Code-Execution using this model, let’s use it to understand a typical infiltration scenario.
A Disrupt-to-Discover (Before vs After) Scenario
Imagine a HR personnel received a malicious CV or resume. What happens when Code-Execution is not disrupted & attacker gains a C2 session over the HR terminal? An attacker can proceed to remotely view Organisation Chart hosted within an Intranet web server as shown below as part of Internal Reconnaisance process; to figure out who’s next (e.g. who are the system admins?):
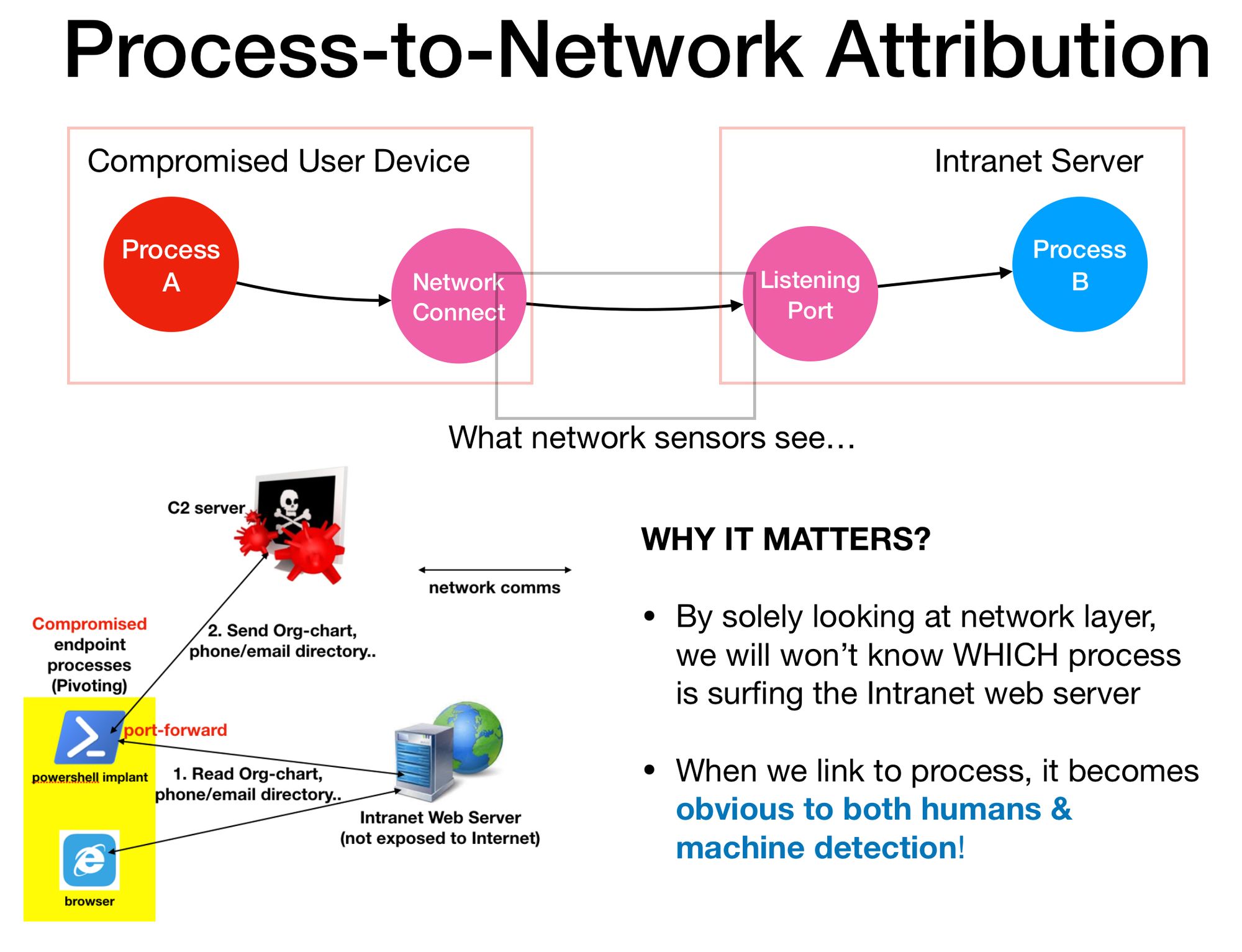
Before
Let’s say the involved offensive technique is custom & fresh from Threat Actors, so no signatures for a novel way of abusing system tools. As far as network layer visibility is concern, there’s really nothing unusual for a HR (compromised) terminal communicating with another network port exposed by Intranet web server, to request for a Org-Chart web-page. What network sensors can see is only up to network addresses & ports. We have no idea of which process is talking to which (yes, the web service is a piece of software) process across the network.
After (Disrupt-to-Discover)
But when we have telemetry (Process → NetworkConnect events) showing us which process is communicating on network, we can now see that there are in fact two distinct processes (Powershell & Browser) connecting to the Intranet Web Server.
As shown in the earlier demo, after switching from profiling to protect mode, the FreeEDR host agent will suspend any “new” process-profile that it has not “seen” before.
Defenders have the benefit of time to investigate carefully because the moment ANY covert unprofiled process that initiates an outbound connection (inclusive of resolving DNS) would be suspended. The attacker does not even have the chance to view the Organisation Chart since it can’t even establish a C2 session!
With appropriate timeline presentation (still working on it, I suck at UI), a defender-analyst can see that the Powershell is launched shortly after viewing the so call “CV” by the affected HR personnel. This background (covert pivot) process is also likely to communicate both to the Internet C2 server & laterally to the Intranet web server.
Even if it were not malicious, the monitoring crew learns a new infrequent system behavior that can be allow-listed & propagated to the rest of the endpoints. Since the guarding host sensor also learns about cross-process activities & which program-processes are often sighted with Parent ProcessID spoofing, any future exploits that spoof or injects into an allowed process to piggy-back egress networks will also be suspended. E.g. The Powershell in the earlier diagram can spawn a hidden browser child process, spoof parent-process as Explorer & then injects codes to start network communications.
Does it mean “DenyList” are useless?
No. It’s simply not useful to track superficial Executable-File features that can permutate very rapidly for free to evade signature-based detection. For Type 1, during profiling, we need to quickly zoom into the files that have “bad” file ownership AND that are egressing to Internet!
https://lolbas-project.github.io tracks various System Abuses (Type 2) for Windows OS. Instead of being concern with every function & tool, we focus on Download & network-access functions. A denylist to highlight commonly abused System Tool file name, which is useful during profiling phase.
What about Admins (aka “Snowden” problem)?
Suppose the scenario was with a Window System Admin, then there’s a chance some system commands (e.g. Powershell) may be communicating on networks. Since my Process-Profiling captured Powershell session as a foreground session & can confirm with the user (who is admin), then future execution of the same or similar CommandLine will be unhindered.
As monitoring operations, we want to zoom into those that are reaching out to the Internet & question: Who owns those destination network assets? Are these destinations part of valid configurations or expected?
When we link process-to-network telemetry to electronic records of Systems Change Management (meaning admins should submit both scheduled & ad-hoc activities) to correlate with commands used or issued by system administrations, such that we can quickly zoom into anomalies that are not part of any legit change requests (admins doing sneaky things).
Reduce Time to Digest Techical Threat Reports!
When we use defensive methods that address a BROAD range of (techniques, the 2nd T in TTP) Type 1 Malware, Type 2 Abuses of system tools & consequentially disrupting Type 3 Multi-Stage Code-Execution, figuring out which reports matter (or to ignore) becomes easier because:
- When Executable Files are written to disk within a standard user session, File-Ownership based Application Control would have blocked it.
- When yet another System Tool to download payloads or “file-less” system abuses that call out to C2 server, host agent will suspend it due to first-sighting.
- Any exploit that does NOT involve tampering with file ownership or able to communicate on network without triggering an OS audit event, are likely to be disrupted when chained with Type 1 &/or 2.
With this Mental Model in mind, (re-)reading technical threat reports with this Code-Execution model-lense will let you notice recurring patterns. Enjoy saving your precious time! You’re welcomed!
Want to learn more? Check out https://jym.sg/cyber-security-in-7-weeks